DBoW Note
Last updated on March 2, 2026 pm
[TOC]
Overview
Bag of Words
BoW(Bag of Words,词袋模型),是自然语言处理领域经常使用的一个概念。一篇文章可能有一万个词,其中可能只有500个不同的单词,每个词出现的次数各不相同。词袋就像一个个袋子,每个袋子里装着同样的词。这构成了一种文本的表示方式。这种表示方式不考虑文法以及词的顺序。
DBoW
在计算机视觉领域,图像通常以特征点及其特征描述来表达。如果把特征描述看做单词,那么就能构建出相应的词袋模型。这就是本文介绍的DBoW2库所做的工作。利用DBoW2库,图像可以方便地转化为一个低维的向量表示。比较两个图像的相似度也就转化为比较两个向量的相似度。它本质上是一个信息压缩的过程。
DBoW算法,来源于西班牙的Juan D. Tardos课题组,用于解决 Place Recognition问题,ORB-SLAM、VINS-Mono等SLAM系统中的闭环检测模块均采用了该算法,主要是基于 词袋模型(BoW) https://en.wikipedia.org/wiki/Bag-of-words_model_in_computer_vision。
主要术语:
- 特征向量(FeatVec) - 单个视觉特征描述子
- 视觉单词 - 词典中的聚类中心,带有权重的单个视觉特征描述子
- 词袋向量(BowVec) - 一张图片用词袋中每个单词是否出现(+ 出现的次数 + TF-DF)组合而成的向量(体现多个视觉特征描述子)
主要过程:
- 构建字典(Vocabulary):将图像数据库转换为索引图(k叉树)
- 近似最近邻(ANN)搜索:将一张图片中特征的描述子通过在k叉树种搜索转换为视觉单词(visual word),多个视觉单词组成词袋向量(BoW Vector)
离线步骤 - 构建视觉字典(聚类问题,也称为无监督分类)
主要采用 K-means算法,将用于训练的图像数据库中的视觉特征(DBoW3中支持ORB和BRIEF两种二进制描述子)归入k个簇(cluster)中,每一个簇通过其质心(centroid)来描述,聚类的质量通常可以用同一个簇的误差平方和(Sum of Squared Error,SSE)来表示,SSE越小表示同一个簇的数据点越接近于其质心,聚类效果也越好。这里的“接近”是使用距离度量方法来实现的,不同的距离度量方法也会对聚类效果造成影响(后面会提到)。
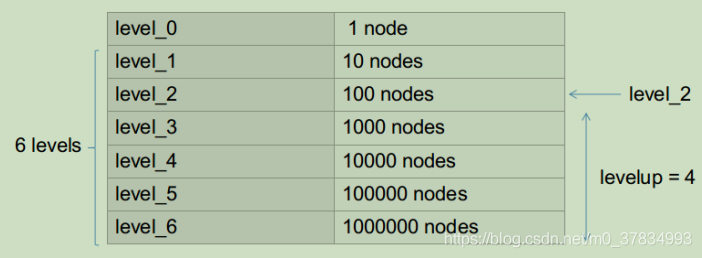
将训练图像数据库中所有N个描述子分散在一个k分支,d深度的k叉树的叶子节点上,如分支数为3,深度为 \(L_w\),这样一个树结构有叶子结点 \(3^{L_w}\) 个。可以根据场景大小、需要达到的效果修改k和d的数值。这样query image进来检索时,可以通过对数时间的复杂度(d次 = logk N)找到其对应的聚类中心,而不是使用O(n)的时间复杂度的暴力检索。据统计,在10000张train image图像数据库中找到query image的匹配图像耗时<39ms,并有较高的召回率和较低的false positive。
然后,为了提高检索时的效率、成功率以及准确率,还采用了下述 权重计算算法
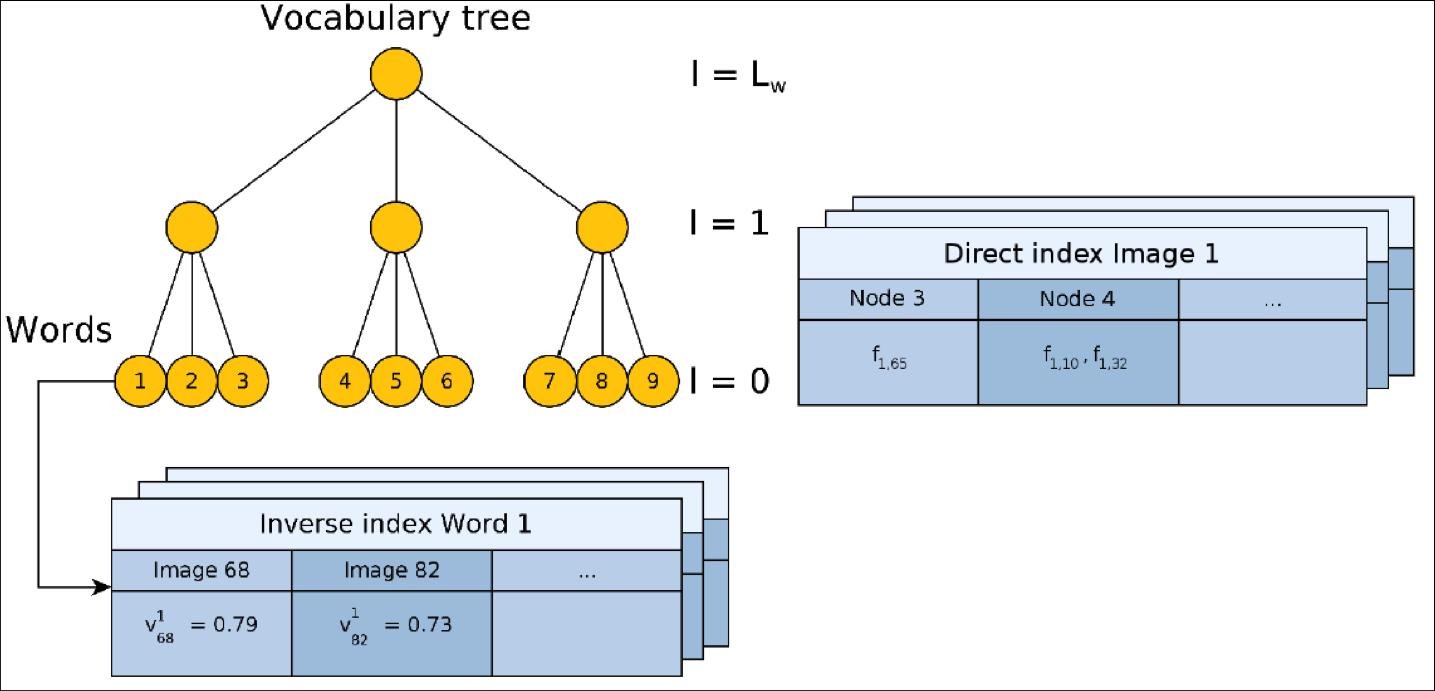
- 倒排索引(Inverse Index)
- 正排索引(Direct Index)
- TF-IDF(Term Frequency - Inverse Document Frequency)
K-means优点是容易实现,缺点是在大规模数据集上收敛较慢,并且可能收敛到局部最小,造成该簇没有代表性。对于描述子这种高维空间的大规模聚类,粗暴使用K-means会有问题。因此会使用其变种Hierarchical K-means 或 K-means++。
实现过程
- 从训练图像中抽取特征
- 将抽取的特征用 k-means++ 算法聚类(使用汉明距离),将描述子空间划分成 k 类
- 将划分的每个子空间,继续利用 k-means++ 算法做聚类
- 重复\(L_w\)
- \(L_w\) 次上述过程,将描述子建立成树形结构,如下图所示
k-means++代码在如下函数:
1 | |
在线步骤 - 近似最近邻检索(ANN Retrieval)
由于ORB和BRIEF描述子均为二进制,因此距离度量采用汉明距离(二进制异或计算)。query image的描述子通过在字典的树上检索(找到最近邻的叶子节点)视觉单词,组成一个词袋向量(BoW vector),然后进行词袋向量之间的相似度计算,得到可能匹配的ranking images。最后还需要利用几何验证等方法选出正确(只是概率最大。。。)的那张图片。
BoW2 in ORB-SLAM2
ORB SLAM中, 在利用帧间所有特征点比对初始化地图点以后, 后面的帧间比对都采用Feature vector进行, 而不再利用所有特征点的descriptor两两比对。这样做的好处当然是 加快了处理速度, 但是信息再次被压缩抽象化, 不可避免会造成性能降低。 然而根据作者在之前的文章[1]及github上的描述, 对一幅图片的BOW特征抽取可以在5ms以内完成, 而在19000张图片构成的database中, 图片搜索可以在10ms内完成, 且保证False Positive为0。 具体的实验我没有进行验证, Whatever, ORB-SLAM证明了这样处理是有效的, 至少在数据集上, 及速度较慢的应用上, 可以实现令人满意的精度。
在作者使用的Bag of Word词典中, 词典是一个事先训练好的分类树, 而BOW特征有两种:
BowVector: 即是分类树中leaf的数值与权重
1
class BowVector:public std::map<WordId, WordValue> {};FeatureVector: 是分类树中leaf的id值与对应输入ORB特征列表的特征序号
1
class FeatureVector:public std::map<NodeId, std::vector<unsigned int> > {};
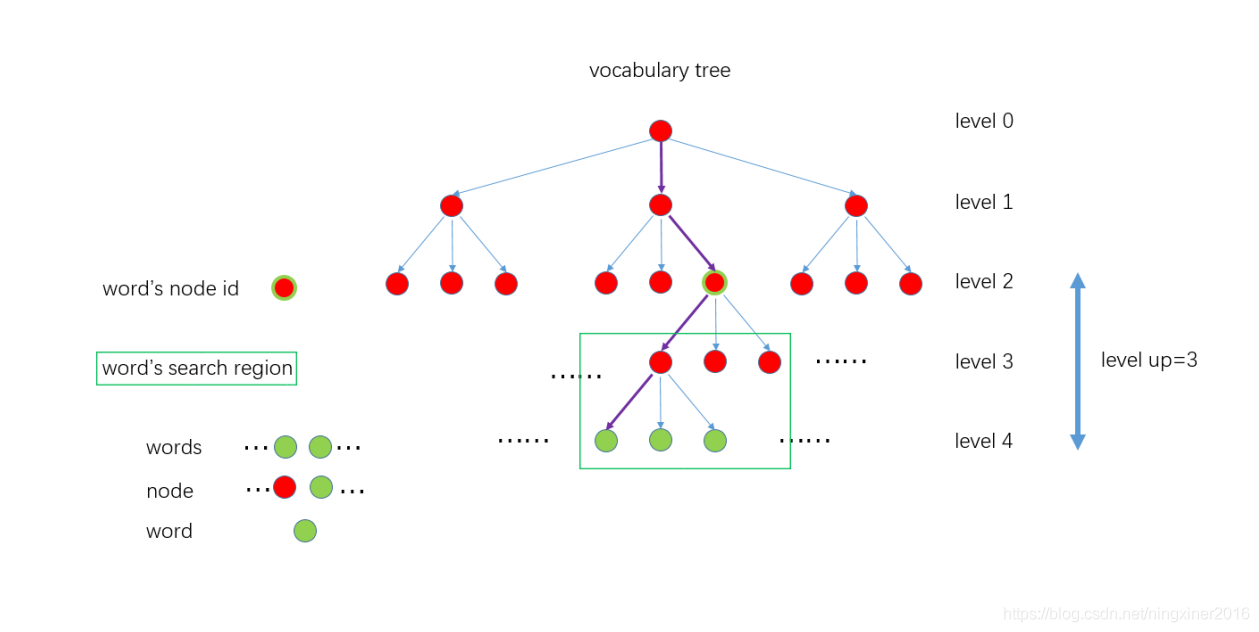
FeatureVector 是为了加速ORB slam中SearchByBow操作,如下图,对于一个6层的字典,ORB slam中levelup设置为4,则level_2的nodeid将会成为FeatureVector中的Key,而每个Key对应一张图像上的若干feature在该帧的索引值。这样在进行两帧图像的特征点匹配的时候就可以只将相同Key值下的特征描述子暴力匹配而不是对两帧图像的所有特征进行暴力匹配,达到加速算法的效果。
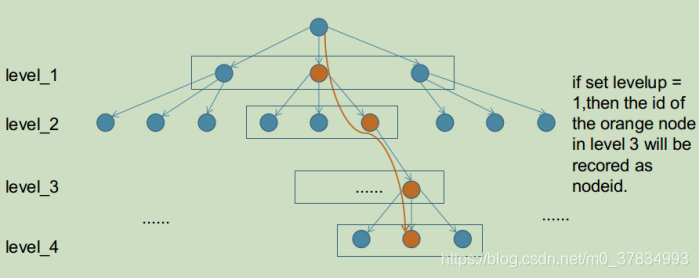
其实处理非常简单, 在已经获得图像特征点集合的基础上, 再根据词典, 对每个特征做一次分类. 再对第二幅图像提取特征, 然后也根据词典, 也对这幅图像的所有特征进行分类. 用分类后的特征类别代替原本的特征descriptor, 即用一个数字代替一个向量进行比对, 显然速度可以大大提升。
正向索引,用于加速匹配
主要在以下几个函数
1 | |
核心代码如下所示:
1 | |
这种加速特征匹配的方法在ORB-SLAM2中被大量使用
- 正向索引的层数如果选择第0层(根节点),那么时间复杂度和暴力搜索一样
- 如果是叶节点层,则搜索范围有可能太小,错失正确的特征点匹配
- 作者一般选择第二层或者第三层作为父节点(L=6),正向索引的复杂度约为O(N2/Km)
逆向索引,用于回环和重定位
作者用反向索引记录每个叶节点对应的图像编号。当识别图像时,根据反向索引选出有着公共叶节点的备选图像并计算得分,而不需要计算与所有图像的得分。
使用词袋模型,在重定位过程中找出和当前帧具有公共单词的所有关键帧,在 KeyFrameDatabase::DetectLoopCandidates() 函数中代码如下:
1 | |
改进
- 通过一些online learning的方法进行词典学习
- 把特征descriptor转为二进制表达, 加速运算
- 训练自己的特征
应用
- SLAM中的 回环检测