When SLAM meets Robotics
PGP目前支持的算法
除非量子计算机落地,目前来说2048位的RSA加密是不可破解的。

1 | |
output
1 | |
其中,Key ID
1 | |
私钥的密码为
1 | |
你日常使用应该使用子密钥,主密钥除了签发新的子密钥不要使用。
建议为不同环境,不同用途都单独生成子密钥,互不干扰。
1 | |
output
1 | |
生成一张"撤销证书",以备以后密钥作废时,可以请求外部的公钥服务器撤销你的公钥
1 | |
output
1 | |
1 | |
output
1 | |
1 | |
1 | |
1 | |
你日常使用应该使用子密钥,主密钥除了签发新的子密钥不要使用。
建议为不同环境,不同用途都单独生成子密钥,互不干扰。
1 | |
1 | |
1 | |
keyserver
配置 默认
1 | |
上传
1 | |
验证邮箱


浏览器搜索查询
搜索
1 | |
output
1 | |
由于公钥服务器没有检查机制,任何人都可以用你的名义上传公钥,所以没有办法保证服务器上的公钥的可靠性。通常,你可以在网站上公布一个公钥指纹,让其他人核对下载到的公钥是否为真。fingerprint参数生成公钥指纹。
1 | |
output
1 | |
1 | |
1 | |
1 | |
output
1 | |
1 | |
1 | |
签名
1 | |
验证
1 | |
1 | |
1 | |
https://docs.github.com/cn/authentication/managing-commit-signature-verification
****能用来放在博客简介里作为身份的象征 增加联系你的安全方式**

涌有了自己pgp key之后,就可以用 gpg-agent 来代替 OpenSSH Agent来进行 SSH操作了。不过替换了之后并不会增加SSH的安全性,额, 折腾精神不死嘛。
硬要说好处的话,大概就可以更方便地使用Yubikey(一种硬件加密智能卡)来SSH。
apt-get update 或者aptitude update出现以下错误:
The following signatures couldn't be verified because the public key is not available: : NO_PUBKEY B5B7720097BB3B58
解决方法:
1 | |
通常移动机器人依赖电机驱动车轮实现行走功能。机器人底盘结构不同,其运动学也完全不同。根据不同类型车轮,常见的底盘结构差速运动模型、滑移运动模型、阿克曼运动模型、全向轮运动模型等等。
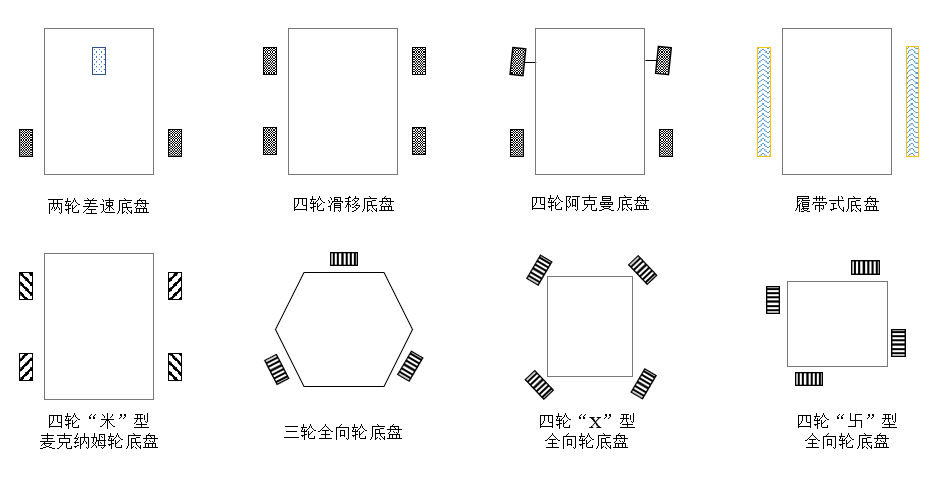
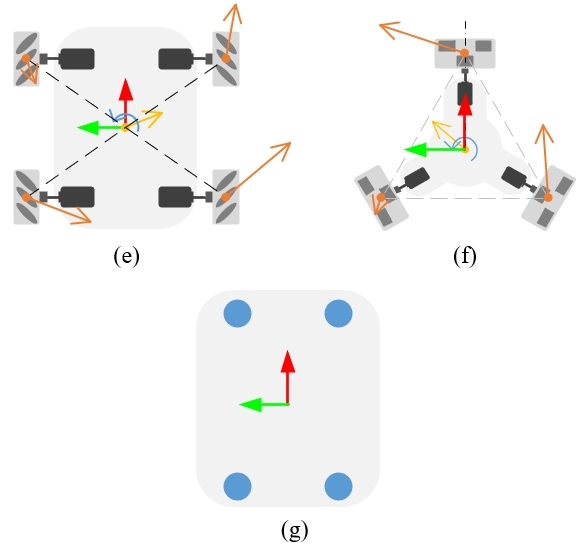
下图中,(a)双轮差速式机器人,(b)阿克曼式机器人,(c)四轮驱动机器人,(d)双履带式机器人,(e)麦克纳姆轮全向机器人,(f)全向轮全向机器人,(g)四轮驱动四轮转向机器人 [2]
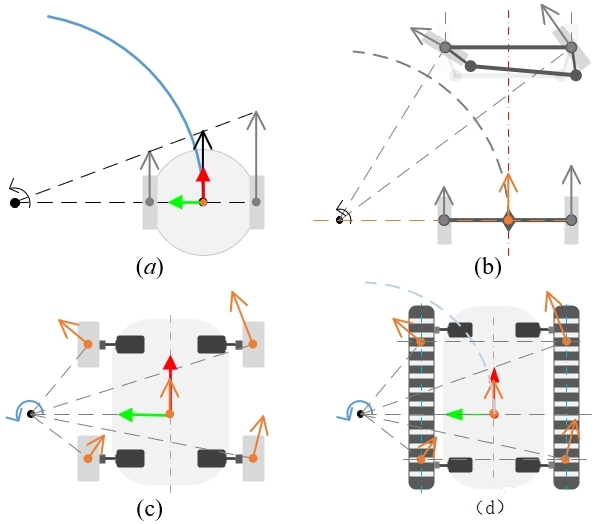
ROS 中运动学分析为正解(Forward kinematics)和逆解(Inverse Kinematics)两种。
双轮差速式机器人的两个动力轮设置在底盘左右两侧,两轮速度可独立控制,通过给定不同速度实现底盘的直线和转向控制。为保持平衡,底盘一般会配有一到两个辅助支撑的万向轮,从而形成三轮或四轮的轮系结构。
ROS自带的DWA路径规划算法比较适合 [3],why?
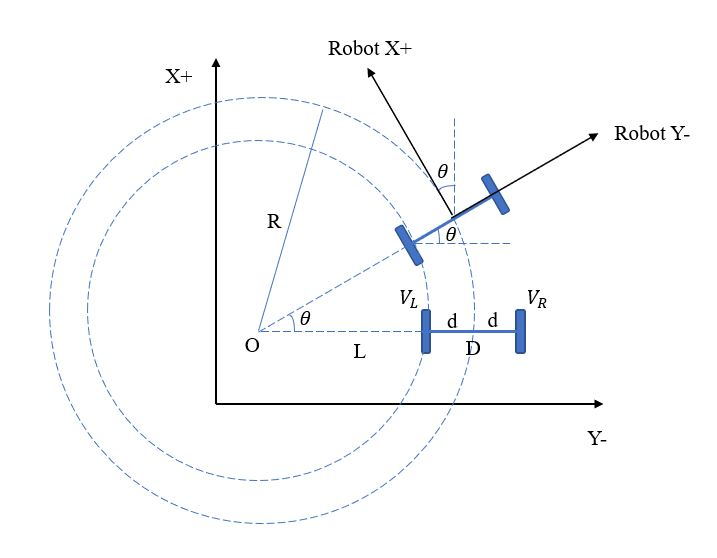

一个驱动轮的速度
车体中心的速度
\[v = \frac{v_l + v_r}{2}\]
求得小车的近似瞬间速度 \(v\) 后,以世界坐标系为原点,对 \(v\) 进行积分,即可得到机器人在世界坐标系中的位姿 \(P\)
\[\dot P = \begin{bmatrix} c & -s & 0 \\ s & c & 0 \\ 0 & 0 & 1 \end{bmatrix}\begin{bmatrix} v_x \\ v_y \\ v_\theta \end{bmatrix}\]
\[P_1 = P_0 + \dot P \cdot \Delta t\]
1 | |
阿克曼式机器人为四轮式,它的原理与汽车相似,由两后轮作为驱动轮提供动力,由两前轮作为转向轮控制方向,且两前轮的转角通过阿克曼转向机构关联。由于采用了与汽车相似的构造,阿克曼式机器人操纵性与汽车类似。
四轮驱动机器人的四个直行轮大小相同、独立驱动且前后、左右对称布置,依靠左右侧直行轮的速度差实现转向。在转弯过程中,四轮驱动机器人是靠滑动摩擦实现的,因此会对直行轮及地面造成一定的磨损。因为存在严重的滑移情况,四轮驱动机器人难以精确控制。
四轮驱动四轮转向机器人(4WD-4WS)相当于有8个电机在控制其运动,可轻松实现机器人的全向运动,具有机构简单、行动灵活、效率高等特点,在室外非结构化场景下具有较强的自适应能力。然而,随着电机数量的增加,对控制的精确性、同步性提出了更高的要求,在一定程度上加大了控制难度。
这类机器人相对比较特殊,车轮采用了 麦克纳姆轮或全向轮,按照一定的规律控制车轮转动,则可以实现前、后、左、右四个方向的全向移动,比起非全向移动机器人,其灵活性更好,能够在狭窄的区域运动。但由于受到麦克纳姆轮或全向轮的限制,该类机器人的承载能力不大。另外,全向移动机器人的各个车轮产生的力会相互抵消一部分,因此同样转矩产生的净推力效率较低,综合效率不如差速式机器人。
双履带式机器人底盘左右两侧各配置一套履带移动机构。每套履带移动机构由轮系、悬挂系统和履带组成。轮系包含若干驱动轮、支重轮、导向轮、托带轮;悬挂系统一般采用克里斯蒂悬挂,以保障越障性能良好;履带一般由强度高、重量轻、模量高、无收缩的复合材料制成。双履带式机器人的越障性能优良,在室外复杂环境中有较多应用。
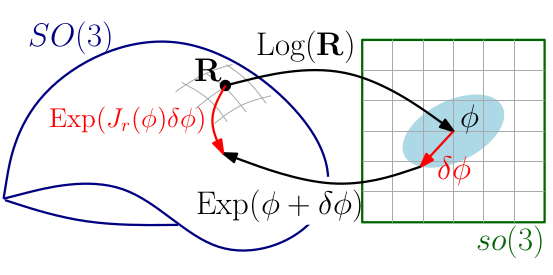
According [1] 2.4,
The idea is that for a \(x \in N\) the function \(g(\delta) := f (x \boxplus \delta)\) behaves locally in \(0\) like \(f\) does in \(x\). In particular \(\|f(x)\|^2\) has a minimum in \(x\) if and only if \(\|g(\delta)\|^2\) has a minimum in \(0\). Therefore finding a local optimum of \(g\), \(\delta = \arg \min_{\delta} \|g(\delta)\|^2\) implies \(x \boxplus \delta = \arg \min_{\xi} \|f(\xi)\|^2\).
\[f(x \boxplus \delta)=f(x)+J_x \delta+\mathcal{O}\left(\|\delta\|^2\right)\]
where
\[J = \left. \frac{\partial f(x \boxplus \delta)}{\partial \delta} \right|_{\delta=0}\quad \longleftrightarrow \quadJ = \left. \frac{\partial f(x)}{\partial x} \right|_{x}\]

\[\left.\mathbf{H} \triangleq \frac{\partial h}{\partial \delta \mathbf{x}}\right|_{\mathbf{x}}=\left.\left.\frac{\partial h}{\partial \mathbf{x}_t}\right|_{\mathbf{x}} \frac{\partial \mathbf{x}_t}{\partial \delta \mathbf{x}}\right|_{\mathbf{x}}=\mathbf{H}_{\mathbf{x}} \mathbf{X}_{\delta \mathbf{x}}\]
lifting and retraction:

\[\left.\mathbf{X}_{\delta \mathbf{x}} \triangleq \frac{\partial \mathbf{x}_t}{\partial \delta \mathbf{x}}\right|_{\mathbf{x}}=\left[\begin{array}{ccc}\mathbf{I}_6 & 0 & 0 \\0 & \mathbf{Q}_{\delta \boldsymbol{\theta}} & 0 \\0 & 0 & \mathbf{I}_9\end{array}\right]\]
the quaternion term
\[\begin{aligned}\left.\mathbf{Q}_{\delta \boldsymbol{\theta}} \triangleq \frac{\partial(\mathbf{q} \otimes \delta \mathbf{q})}{\partial \delta \boldsymbol{\theta}}\right|_{\mathbf{q}} &=\left.\left.\frac{\partial(\mathbf{q} \otimes \delta \mathbf{q})}{\partial \delta \mathbf{q}}\right|_{\mathbf{q}} \frac{\partial \delta \mathbf{q}}{\partial \delta \boldsymbol{\theta}}\right|_{\delta \hat{\boldsymbol{\theta}}=0} \\&=\left.\left.\frac{\partial\left([\mathbf{q}]_L \delta \mathbf{q}\right)}{\partial \delta \mathbf{q}}\right|_{\mathbf{q}} \frac{\partial\left[\begin{array}{c}1 \\\frac{1}{2} \delta \boldsymbol{\theta}\end{array}\right]}{\partial \delta \boldsymbol{\theta}}\right|_{\hat{\delta}=0} \\&=[\mathbf{q}]_L \frac{1}{2}\left[\begin{array}{lll}0 & 0 & 0 \\1 & 0 & 0 \\0 & 1 & 0 \\0 & 0 & 1\end{array}\right]\end{aligned}\]

1 | |
Retraction
\[\boxplus(x, \Delta)=x \operatorname{Exp}(\Delta)\]
global w.r.t local
\[J_{GL} = \frac{\partial x_G}{\partial x_L}= D_2 \boxplus(x, 0) = \left. \frac{\partial \boxplus(x, \Delta)}{\partial \Delta} \right|_{\Delta = 0}\]
参考 [9]
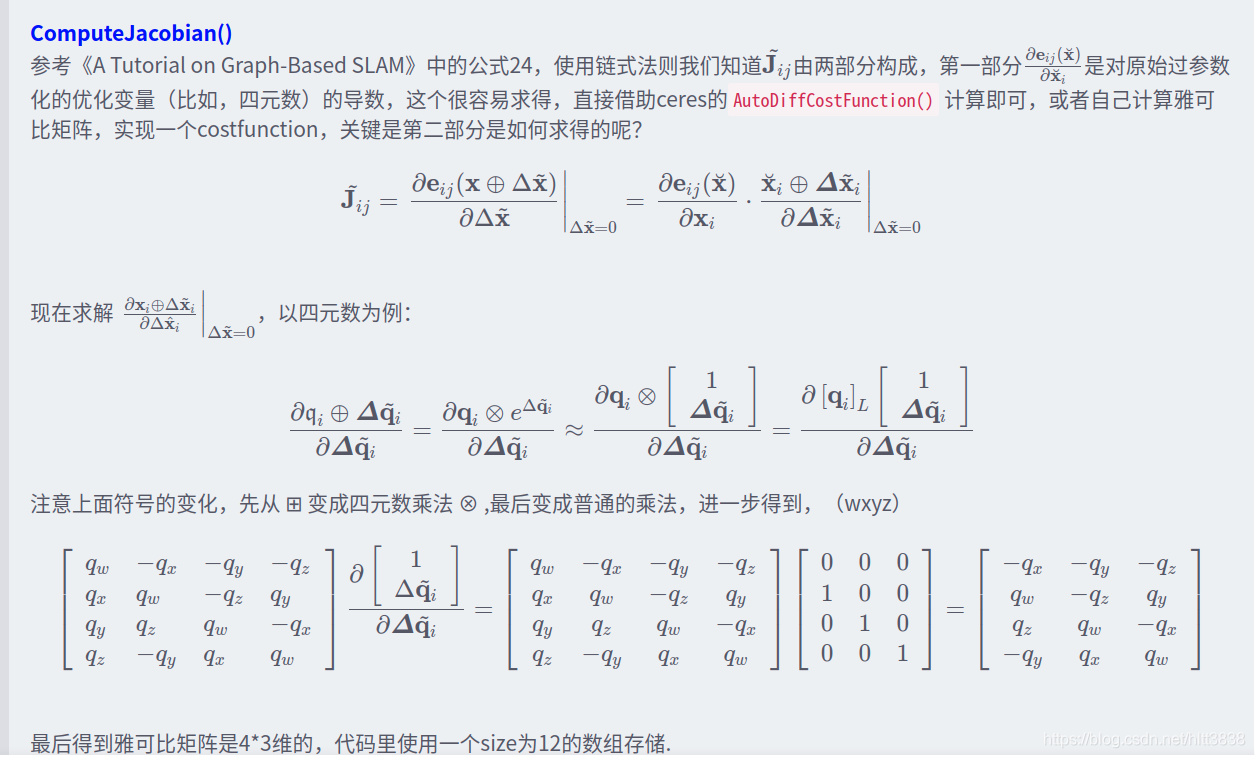
在 ceres::CostFunction 处提供 residuals 对 Manifold 上变量的导数
\[J_{rG} = \frac{\partial r}{\partial x_G}\]
则 对 Tangent Space 上变量的导数
\[J_{rL} = \frac{\partial r}{\partial x_L}= \frac{\partial r}{\partial x_G} \cdot J_{GL}\]
参考 [7]

Quaternion in Eigen
1 | |
Quaternion in Ceres Solver
wxyzThe iframe tag below would show a 640x480px image with ID 550092599700936.
1 | |
What is observability ?
In control theory, observability is a measure for how well internal states of a system can be inferred by knowledge of its external outputs.
What is consistency ?
A recursive estimator is consistent when the estimation errors are zero-mean and have covariance matrix equal to that reported by the estimator.
Observability \(\longrightarrow\) Consistency
Mismatch (actual vs true) in observability \(\longrightarrow\) Inconsistency
VINS observability properties \(\longrightarrow\) estimator inconsistency

已知,光滑标量函数 \(h\) 以及 光滑向量场 \(f\) 和 \(g\)
\[\begin{aligned}h(x):& \; R^n \rightarrow R \\f(x):& \; R^n \rightarrow R^n \\g(x):& \; R^n \rightarrow R^n\end{aligned}\]
行向量 梯度 \(\nabla h\) 乘以 向量场 \(f\),其结果 \(L_f h\) 正好是个标量
\[L_f h = \nabla h \cdot f = \left( \frac{\partial h}{\partial x} \right)^T f\]
\(L_g L_f h\) 结果依然是个标量
\[L_g L_f h = L_g (L_f h) = \nabla(L_f h) g = \left( \frac{\partial (L_f h)}{\partial x} \right)^T g= \left( \frac{\partial \left( (\frac{\partial h}{\partial x})^T f \right)}{\partial x} \right)^T g\]
总结一下:Lie Derivative与一般的Derivative的区别是,Lie Derivative是定义在两个函数 \(h\) 和 \(f\) 之间的,它俩都是向量 \(x\) 的函数,通过共同的 \(x\) 联系起来;一般的Derivative是某个函数对 \(x\) 定义的。
what: 控制理论中的 可观察性(observability)[3] 是指系统可以由其外部输出推断其内部状态的程度。
why: 为了能让系统不可观的维度与真实系统一致,从而提高系统精度
how: 通过计算可观性矩阵,分析其零空间的秩,来分析系统哪些状态维度可观/不可观;可观性矩阵对应系统可观测的维度,零空间对应系统不可观的维度
Discrete state space equations of nonlinear systems (linearized without considering noise) is
\[\begin{cases} x_{k+1} = \Phi_k x_k \\ y_k = H_k x_k \end{cases}\]
according to the Lie derivative, the observability matrix is
\[\mathbf{\mathcal{O}} \left(\mathbf{x}^{\star}\right) =\left[ \begin{array}{c} \mathbf{H}_{1} \\ \mathbf{H}_{2} \boldsymbol{\Phi}_{2,1} \\ \vdots \\ \mathbf{H}_{k} \boldsymbol{\Phi}_{k, 1} \end{array}\right]\]
then, the unobservable dimensions of the system are
\[\text{rank}(N(\mathcal{O}))\]
对于SLAM系统而言(如单目VO),当我们改变状态量时,测量不变意味着损失函数不会改变,更意味着求解最小二乘时对应的信息矩阵H存在着零空间。
for the monocular VO based on optimization methods, the dimension of null space of the Hessian (Information) matrix \(H\) is 7, that is, the unobservable dimensions are
\[\text{rank}(N(H)) = 7\]
\[J^T J \Delta x = - J^T r \quad \longrightarrow \quad H \Delta x = b\]
What is the relationship between the Hessian matrix \(H\) and the observability matrix \(\mathcal{O}\) in the optimization based VO/VIO ?
贺一家博士给的总结:

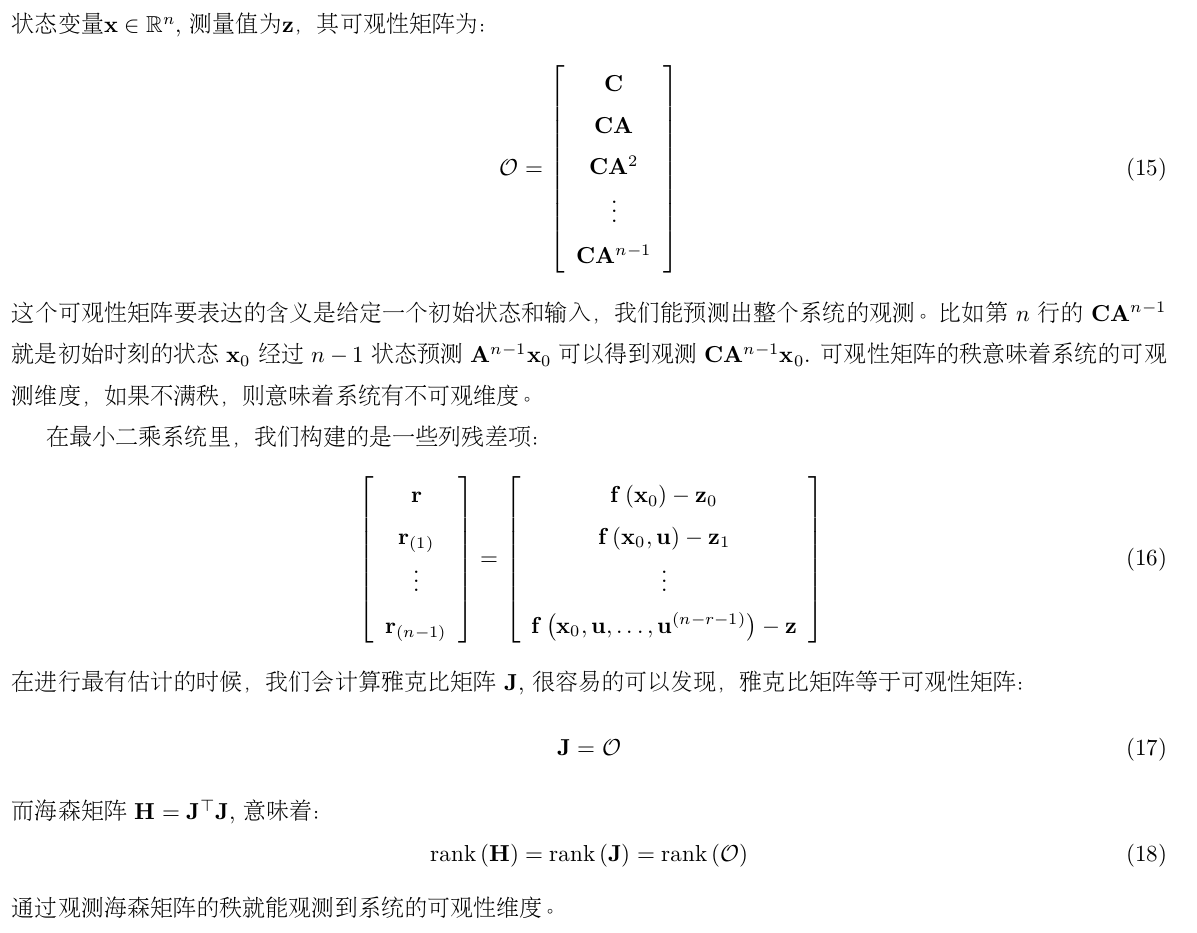
a state estimator is consistent if the estimation errors (i) are zero-mean, and (ii) have covariance matrix smaller or equal to the one calculated by the filter.
open_vins #171: Consistency maintenance methods, FEJ vs Observability-constrained(OC) ones
paper:
paper: A First-Estimates Jacobian EKF for Improving SLAM Consistency
estimation from the first time
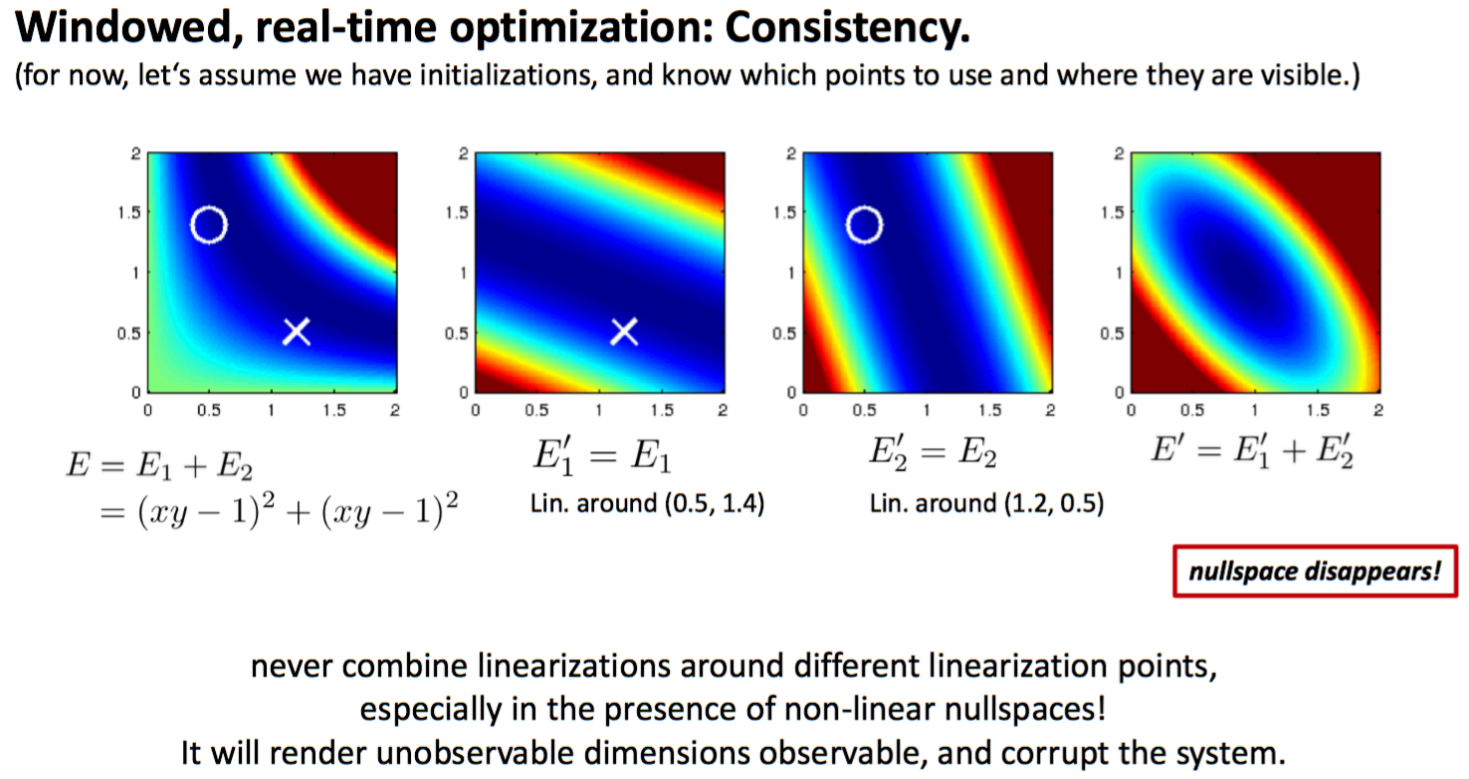
to ensure that the state transition and Jacobian matrices are evaluated at correct linearization points such that the above observability analysis will hold true
FEJ 算法:不同残差对同一个状态求雅克比时,线性化点必须一致,这样就能避免零空间退化而使得不可观变量变得可观。
app:
ref:
TODO

MSCKF-VIO (S-MSCKF):
Modification of the State Transition Matrix \(\Phi\)
1 | |
Modification of the Measurement Jacobian \(H\)
1 | |
It is well known that visual-inertial systems have four degrees of freedom that are not observable: the global position and the rotation around gravity. These unobservable degrees of freedom (called gauge freedom) have to be handled properly in visual-inertial state estimation to obtain a unique state estimate.
H有正确的零空间,比如,对于单目VO,rank(N(H)) = 7,则H为奇异矩阵,那么增量方程始终存在病态或求解不稳定问题;通过处理 规范自由度 解决。
In optimization-based methods, three approaches are usually used:


ref:
1 | |
test
1 | |
1 | |
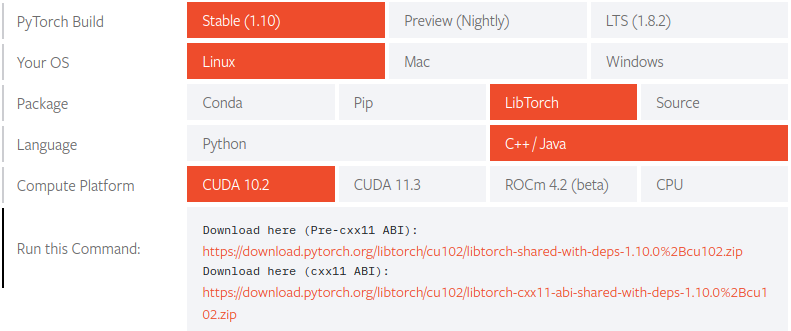
Dowload the prebuilt libs
1 | |
Build from Source
1 | |
The built libtorch library is located at pytorch/torch/lib/tmp_install/ in default.
1 | |
use with cmake
1 | |
include dir
1 | |
torch.jit.trace 转换后得到 .pt 文件只保存模型参数,不保存模型结构
1 | |
保存整个模型,包括模型结构+模型参数
1 | |
UserWarning: CUDA initialization: CUDA unknown error - this may be due to an incorrectly set up environment, e.g. changing env variable CUDA_VISIBLE_DEVICES after program start. Setting the available devices to be zero
1 | |
Darknet: Open Source Neural Networks in C
YOLO: Real-Time Object Detection
1 | |
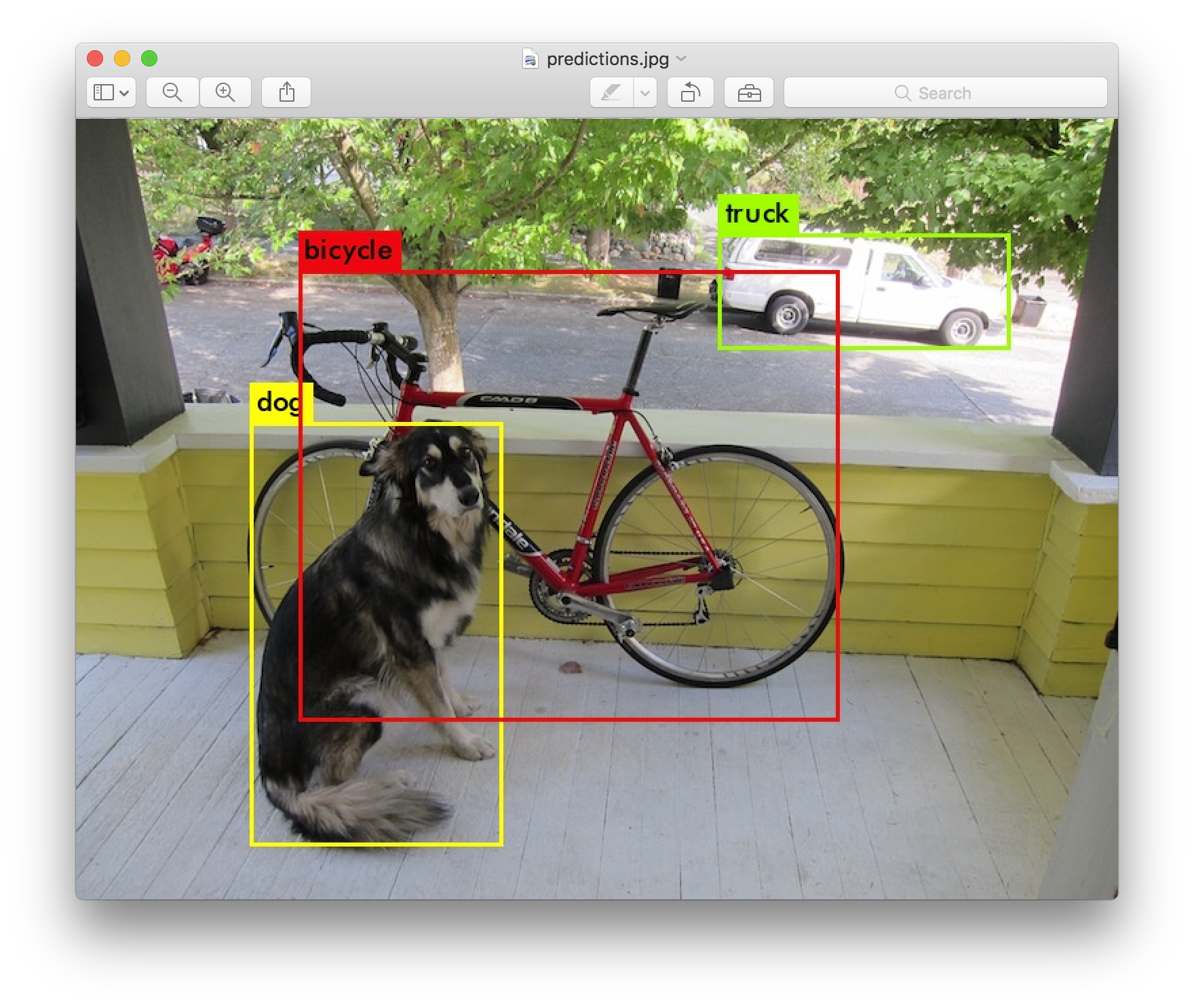
output
1 | |
fixed CUDA Error with the cfg code below
out of memory
1 | |
配置文件 yolov3.cfg 内容如下
1 | |
https://github.com/leggedrobotics/darknet_ros
YOLO ROS: Real-Time Object Detection for ROS
darknet_ros.launch
1 | |
ros.yaml
1 | |
1 | |
The auto exposure code is not open source because for one the actual implementation is ugly, and second because it ties into other software that is not open sourced.
Here a few (edited) notes that I sent to somebody who asked about how it works:
what we implemented is super simple but works well in practice:
\[ \text{new-shutter-time} = \text{current-shutter-time} \cdot \frac{\text{desired-brightness}}{\text{current-brightness}} \]
You can go fancier by implementing
\[ \text{new-shutter-time} = \text{current-shutter-time} \cdot \left(\frac{\text{desired-brightness}}{\text{current-brightness}}\right)^\alpha\]
\(\alpha \leq 1\), but in practice \(\alpha = 1\) works just fine.
brightness is computed from every 16th row and column, so in fact only 1 out of every 256 is used for brightness computation
threshold on brightness:
we only change shutter time if
\[ |\text{desired-brightness} - \text{current-brightness}| > \text{threshold}\]
This is so that we don't torture the ptgrey cameras with constant shutter speed changes.
region of interest (ROI) support: we compute brighness only from the bottom X%. Typically X=70, so we will ignore the top 30% of the image, because that's often where the sun or sky are, and where we don't usually pick up features.
configurable max shutter limit: the max shutter time is the min of the shutter time imposed by frame rate, and a configurable hard shutter limit (in case we get motion blur and decide we'd rather live with a darker image and/or gain noise than the motion blur).
auto gain: once we hit max shutter, we turn on auto gain (and when it get's brighter again, we take the gain off first, then decrease shutter).
So
\[\text{if} \; \left| \bar{B} - B_c \right| > B_{th}: \\ \; T_s \leftarrow T_s \cdot \frac{\bar{B}}{B_c} \\ \; \text{if} \; T_s < T_{min}: \\ \text{auto gain}\]
image_exposure_control for RS cam [2]
vo-autoexpose [3] : An auto-exposure algorithm for maxing out VO performance in challenging light conditions
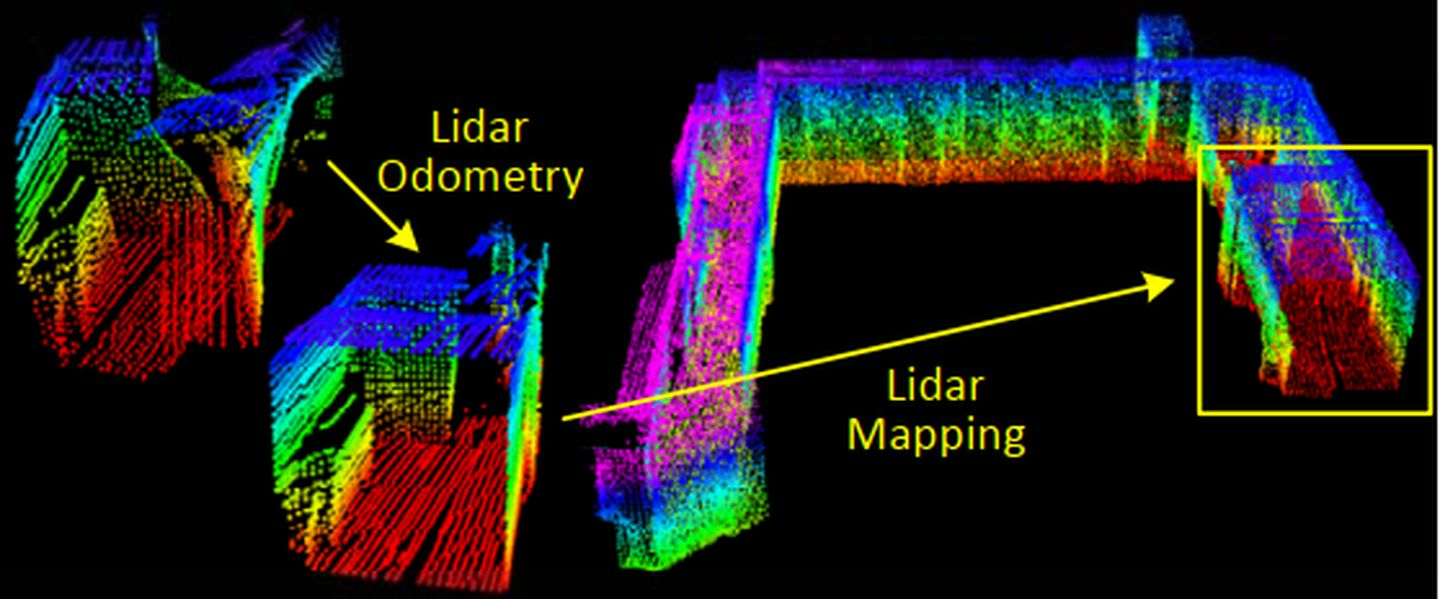
A-LOAM is an Advanced implementation of LOAM (J. Zhang and S. Singh. LOAM: Lidar Odometry and Mapping in Real-time), which uses Eigen and Ceres Solver to simplify code structure.
Code: A-LOAM 注释版
ROS Graph

Pipeline



数据清洗
1 | |
按线数保存的点云集合
1 | |
曲率计算 (使用每个点的前后五个点)
1 | |
根据曲率进行点云特征提取,将每条线上的点分入相应的类别:边沿点和平面点
对于每条线
对于每一份,曲率大于0.1的点
cornerPointsSharp,同时 cloudLabel[ind] = 2cornerPointsLessSharp,同时 cloudLabel[ind] = 1对于每一份,曲率小于0.1的点
surfPointsFlat,同时 cloudLabel[ind] = -1对于每一份,将剩余的点 cloudLabel[k] <= 0(包括之前被排除的点)全部归入平面点 surfPointsLessFlatScan
运动畸变示意图如下
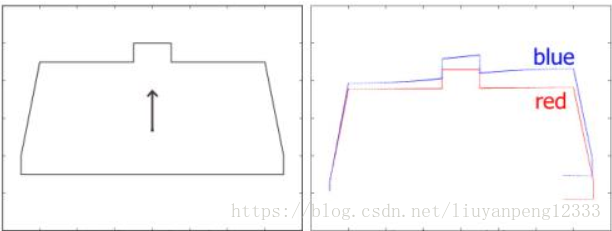
Reprojecting point cloud to the end of a sweep
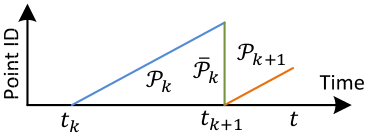
1 | |
当前点 curr_point 与 线段 匹配,找到线段的两个端点
last_point_a: KDTree 搜索最近的点last_point_b: 在scan增长和下降的方向上分别搜索,不在同一scan但处于一定阈值scan范围内,距离最小的点当前点 curr_point 与 面 匹配,找到面的三个点
last_point_a: KDTree 搜索最近的点
last_point_b: 在scan增长(intensity<=closestPointScanID)和下降(intensity>=closestPointScanID)的方向上分别搜索,处于一定阈值scan范围内,距离最小的点
last_point_c: 在scan增长(intensity>closestPointScanID)和下降(intensity<closestPointScanID)的方向上分别搜索,处于一定阈值scan范围内,距离最小的点
残差度量方式
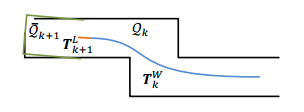
LOAM采用的是栅格(cube)地图的方法,将整个地图分成21×21×11个珊格,每个珊格是⼀个边⻓50m的正⽅体,当地图逐渐累加时,珊格之外的部分就被舍弃,这样可以保证内存空间不会随着程序的运⾏⽽爆掉,同时保证效率。
将当前帧已经消除畸变的点云转换到全局坐标系 transformAssociateToMap(),然后与局部地图(local map或者称为submap,源码中使用的是三维栅格cube做的局部地图管理)做特征匹配
用于特征匹配的局部地图 (local map)
1 | |
当前点 curr_point 与 线段 匹配,找到线段的两个端点
KDTree 搜索最近的5个点(最远点距离小于1米),计算其中心点 center,并构建协方差矩阵;如果是线特征,协方差矩阵最大特征值对应的特征向量即为线的方向向量 unit_direction,然后根据中心点和方向向量得到两个端点
last_point_alast_point_b当前点 curr_point 与 面 匹配,找到面的法向量
KDTree 搜索最近的5个点(最远点距离小于1米),计算面的法向量
残差度量方式
计算出的位姿修正Odometry的位姿
获得 laserCloudCornerArray 和 laserCloudSurfArray,并降采样;当地图逐渐累加时,珊格之外的部分就被舍弃,这样可以保证内存空间不会随着程序的运⾏⽽爆掉,同时保证效率。
1 | |
OpenMVG provides an end-to-end 3D reconstruction from images framework compounded of libraries, binaries, and pipelines.

OpenMVS (Multi-View Stereo) is a library for computer-vision scientists and especially targeted to the Multi-View Stereo reconstruction community.
aims at filling that gap by providing a complete set of algorithms to recover the full surface of the scene to be reconstructed
The input is a set of camera poses plus the sparse point-cloud and the output is a textured mesh
Modify the code below in SfM_SequentialPipeline.py, SfM_GlobalPipeline.py or tutorial_demo.py
1 | |
then
1 | |
MVG (SfM scene) to MVS
1 | |
Viewer module can be used to visualize any MVS project file or PLY/OBJ file.
1 | |
1 | |
1 | |
1 | |
MeshInfo1 | |
VertexInfoAdd faces to their three vertices
VertexInfoClassify each vertex and compute adjacenty info
AdjacentFaceList adj_temp for orderingdigraph { face_id [color=green]; front_vid [color=blue]; back_vid [color=blue];
AdjFaceTmp->face_id AdjFaceTmp->front_vid AdjFaceTmp->back_vid }graph { layout=twopi; node [shape=circle];
v0 [color="red"]; v1 [color="blue"]; v2 [color="blue"];
v0--v1 [color=green]; v0--v2 [color=green]; v0--v3; v0--v4; v1--v2 [color=green]; v3--v2; v3--v4; v1--v4;
overlap=false; }Sort adjacent faces by chaining them
1 | |
update VertexInfo
digraph { vclass; verts [color=blue]; faces [color=green];
vinfo->vclass; vinfo->verts; vinfo->faces; }UniGraph)1 | |
对于每个 face,将mesh中与其每条 edge 邻接的 face 存入 adj_faces;将当前 face 与 adj_faces 中每个 face 建立 edge,构建 UniGraph 。
graph { node [shape=circle];
f0--f1; f1--f2; f0--f3; f3--f4; f1--f4;
overlap=false; }1 | |
Calculates the data costs for each face and texture view combination, if the face is visible within the texture view.
1 | |
FaceProjectionInfo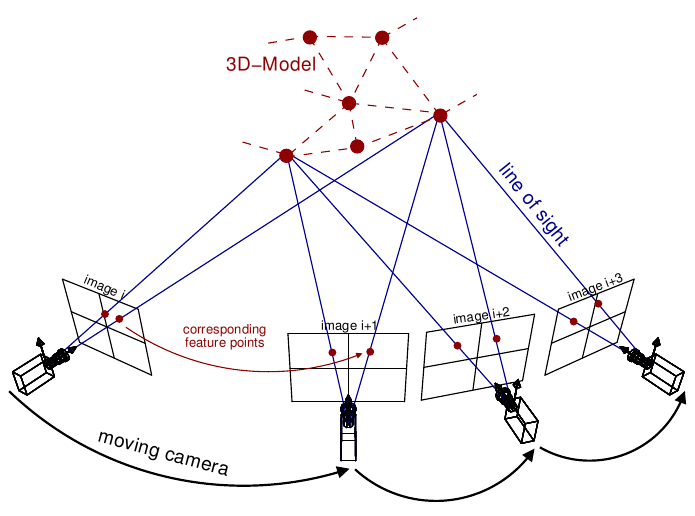
1 | |
create hist_qualities::Histogram using info.quality, and get the upper_bound when percentile=0.995
compute data cost
1 | |
| DataCost | face0 | face1 | ... | faceN |
|---|---|---|---|---|
| view0 | ||||
| view1 | ||||
| ... | ||||
| viewN |
mapmap::Graph<cost_t>mapmap::LabelSet<cost_t, simd_w>| view id | face0 | face1 | ... | faceN |
|---|---|---|---|---|
| view0 | ||||
| view1 | ||||
| ... | ||||
| viewN |
1 | |
| face_id | label_set | costs | |
|---|---|---|---|
| unary0 | |||
| unary1 | |||
| ... | |||
| unaryN |
1 | |
1 | |
The aim is to find a labeling for X that produces the lowest energy.
energy/cost function:
\[\text{energy} (Y, X) = \sum_{i} \text{DataCost} (y_i, x_i) + \sum_{j = \text{neighbours of i}} \text{SmoothnessCost} (x_i, x_j)\]
by OpenMVS
1 | |
Generates texture patches using the graph to determine adjacent faces with the same label.

without seam levelling

generate TextureAtlas from all of TexturePatch

1 | |

上述纹理重建属于 计算机视觉 的内容,本节是其逆过程,属于 计算机图形学 的内容。
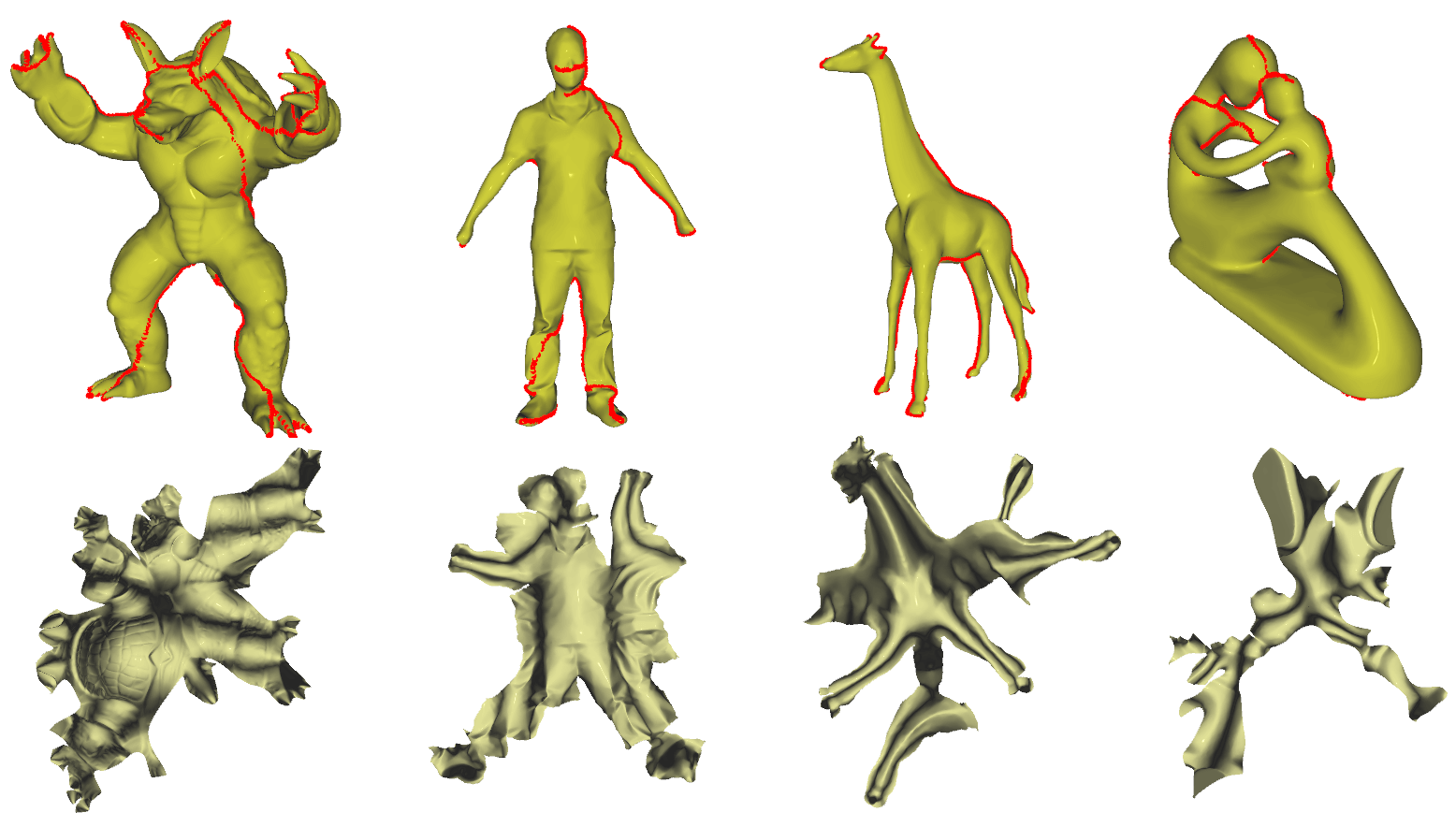
Kinect Fusion 描述三维空间的方式叫 Volumetric。它把固定大小的一个空间(比如3𝑚×3𝑚×3𝑚)均匀分割成一个个小方块(比如512×512×512),每个小方块就是一个voxel,存储TSDF值以及权重。最终得到的三维重建就是对这些voxel进行线性插值。
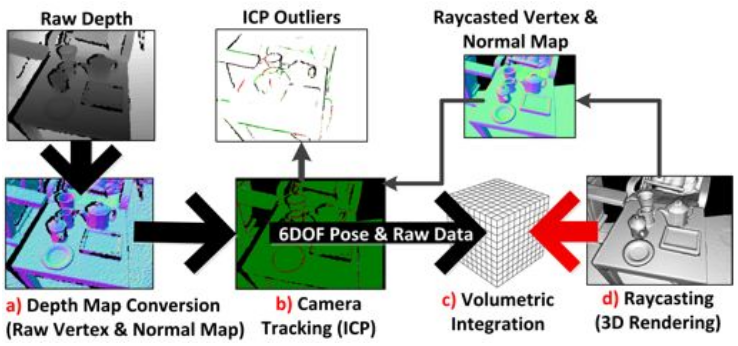
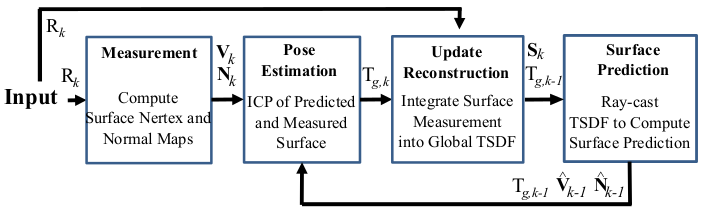
重建流程如上图所示:
Depth Map Conversion: 读入的深度图像转换为三维点云并且计算每一点的法向量
Camera Tracking (map-to-frame ICP): 计算得到的带有法向量的点云,和通过光线投影算法根据上一帧位姿从模型投影出来的点云,利用 ICP 算法配准计算位姿
Volumetric Integration: 根据计算得到的位姿,将当前帧的点云融合到网格模型中去,这里用到了TSDF
Raycasting (光线投影算法): 根据当前帧相机位姿利用该算法从模型投影得到当前帧视角下的点云,并且计算其法向量,用来对下一帧的输入图像配准
如此是个循环的过程,通过移动相机获取场景不同视角下的点云,重建完整的场景表面。
Project:
KinectFusion: real-time 3D reconstruction and interaction using a moving depth camera

构建三层金字塔的目的是为了从粗到细地计算相机位置姿态,有加速计算的效果。
相机的位置姿态是用ICP (Iterative Closest Point) 求解的。ICP是处理点云的常规手段,通过最小化两块点云的差别,迭代求解出拍摄两块点云的相机之间的相对位置。
有不同的方式来描述点云的差别,最常用的是point-to-point和point-to-plane两种。KinectFusion选择的是point-to-plane的方式,要把点到点的距离向法向量投影。point-to-plane要比point-to-point收敛速度快很多,而且更鲁棒。
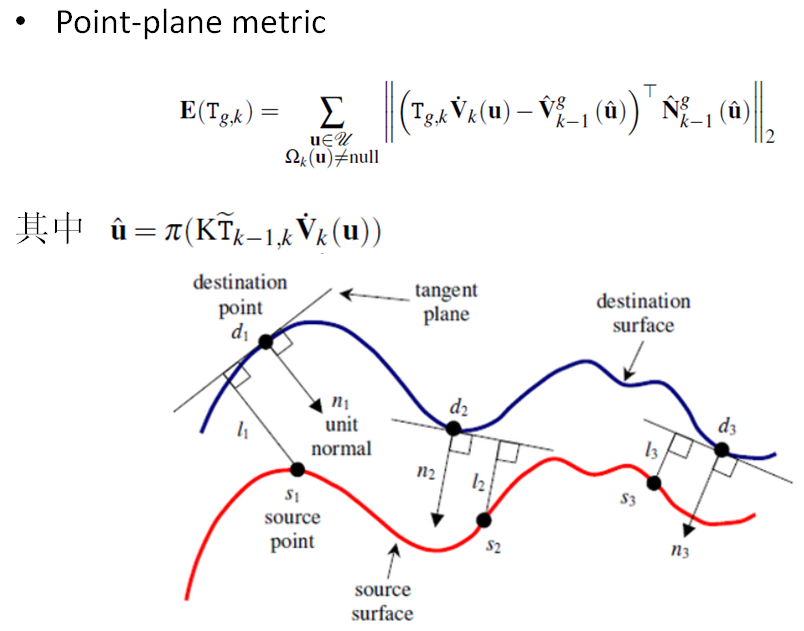

KinectFusion 算法采用 frame-to-model (通过当前帧深度图像转换得到的点云,和根据上一帧相机位姿从模型投影获取的深度图像转换得到的点云进行配准)的方式,而不是采用 frame-to-frame (通过当前帧深度图像转换得到的点云,和上一帧深度图像转换得到的点云进行配准)的形式计算两帧位姿,作者论文里也验证了采用 frame-to-model 的形式重建要更加准确。
假设pose estimation已经计算出来,就可以把本次测量结果融合到全局地图(global model)中了。
这里的model使用的是TSDF地图。

更新完TSDF值之后,就可以用TSDF来估计 voxel/normal map。这样估计出来的voxel/normal map比直接用RGBD相机得到的深度图有更少的噪音,更少的孔洞(RGBD相机会有一些无效的数据,点云上表现出来的就是黑色的孔洞)。估计出的voxel/normal map与新一帧的测量值一起可以估算相机的位置姿态。
具体的表面估计方法叫Raycasting。这种方法模拟观测位置有一个相机,从每个像素按内参𝐾投射出一条射线,射线穿过一个个voxel,在射线击中表面时,必然穿过TSDF值为一正一负的两个紧邻的voxel(因为射线和表面的交点的TSDF值为0),表面就夹在这两个voxel里面。然后可以利用线性插值,根据两个voxel的位置和TSDF值求出精确的交点位置。这些交点的集合就呈现出三维模型的表面。
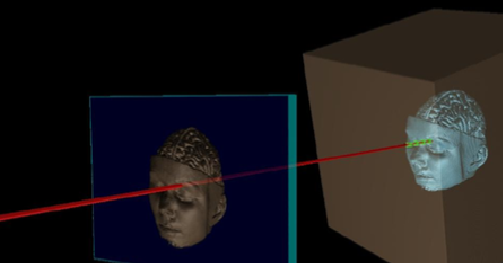
如图:从光心出发,穿过像素点在网格模型中从正到负的穿越点,就表示在当前像素点处可以看到的重建好的场景的表面。对于每个像素点,分别做类似的投影,就可以计算得到的在每个像素点处的点云。
采用光线投影算法计算得到的点云,再计算其法向量,用带法向量的点云和下一帧的输入图像配准,计算下一帧输入图像的位姿。如此是个循环的过程。
其实,到此KinectFusion的流程已经结束了,重建出了点云格式的表面三维模型;但在实际应用中,尤其AR领域,还需要Mesh格式的三维模型,甚至需要纹理贴图等。
通过Marching Cube对重建后的点云实现三角面片重建。
点云数据在三维空间中为离散表示,对TSDF地图使用Marching Cube算法来对等值面进行提取,实现三角面片重建。
Marching Cube算法基本思想是逐个处理标量场中的体素,分离出与等值面相交的体素,采用插值计算出等值面与立方体边的交点。根据立方体每一顶点与等值面的相对位置,将等值面与立方体边的交点按一定方式连接生成等值面,作为等值面在该立方体内的一个逼近表示。
Marching Cube用来提取TSDF体素中隐含存储的三维网格模型,实际上是提取TSDF中的0等值曲面。首先,遍历操作,通过遍历TSDF网格,定位并记录下与0等值曲面相交的体素点;然后,提取操作,对于前面记录下来的体素点,利用预存的网格索引及线性插值方法,提取出三角形面片网格,得到重建的三维几何模型。
上面 KinectFusion 的几个步骤属于 几何重建 的过程,而在实际中,尤其AR领域,还要给 三维模型 进行 纹理重建 (纹理贴图)。
Kintinuous: Spatially Extended KinectFusion
https://github.com/sjy234sjy234/KinectFusion-ios
example main.props, 在此文件 设置工程,方便分享
1 | |
example file
1 | |
example Windows Batch file config.bat
1 | |
from cmd with cmake --build
1 | |
打开 Visual Studio 工程 xxx.sln,生成解决方案
1 | |
在 线性化点 \(x_0=1\) 泰勒展开
\[\sqrt{x} \cong 1+\frac{1}{2}(x-1)-\frac{1}{4} \frac{(x-1)^{2}}{2 !}+\frac{3}{8} \frac{(x-1)^{3}}{3 !}-\frac{15}{16} \frac{(x-1)^{4}}{4 !}+\cdots\]
根据该公式我们可以在一定精度内逼近真实值,不过这个公式仍然存在一个问题,即是公式的收敛问题。
在泰勒级数展开中,平方根函数的公式当且仅当参数值位于一个有效范围内时才有效,在该范围内计算趋于收敛。该范围即是收敛半径,当我们对平方根函数用 \(x_0=1\) 进行计算时,泰勒级数公式希望x处于范围: \(0<x<2\) 之间。如果x在收敛半径之外,则展开式中的项会越来越大,泰勒级数离答案也就越来越远。为了解决该问题,我们可以考虑当待开平方数大于4时以4去除它,最后将得到的数乘以相同次数的2即可。
BoW(Bag of Words,词袋模型),是自然语言处理领域经常使用的一个概念。一篇文章可能有一万个词,其中可能只有500个不同的单词,每个词出现的次数各不相同。词袋就像一个个袋子,每个袋子里装着同样的词。这构成了一种文本的表示方式。这种表示方式不考虑文法以及词的顺序。
在计算机视觉领域,图像通常以特征点及其特征描述来表达。如果把特征描述看做单词,那么就能构建出相应的词袋模型。这就是本文介绍的DBoW2库所做的工作。利用DBoW2库,图像可以方便地转化为一个低维的向量表示。比较两个图像的相似度也就转化为比较两个向量的相似度。它本质上是一个信息压缩的过程。
DBoW算法,来源于西班牙的Juan D. Tardos课题组,用于解决 Place Recognition问题,ORB-SLAM、VINS-Mono等SLAM系统中的闭环检测模块均采用了该算法,主要是基于 词袋模型(BoW) https://en.wikipedia.org/wiki/Bag-of-words_model_in_computer_vision。
主要术语:
主要过程:
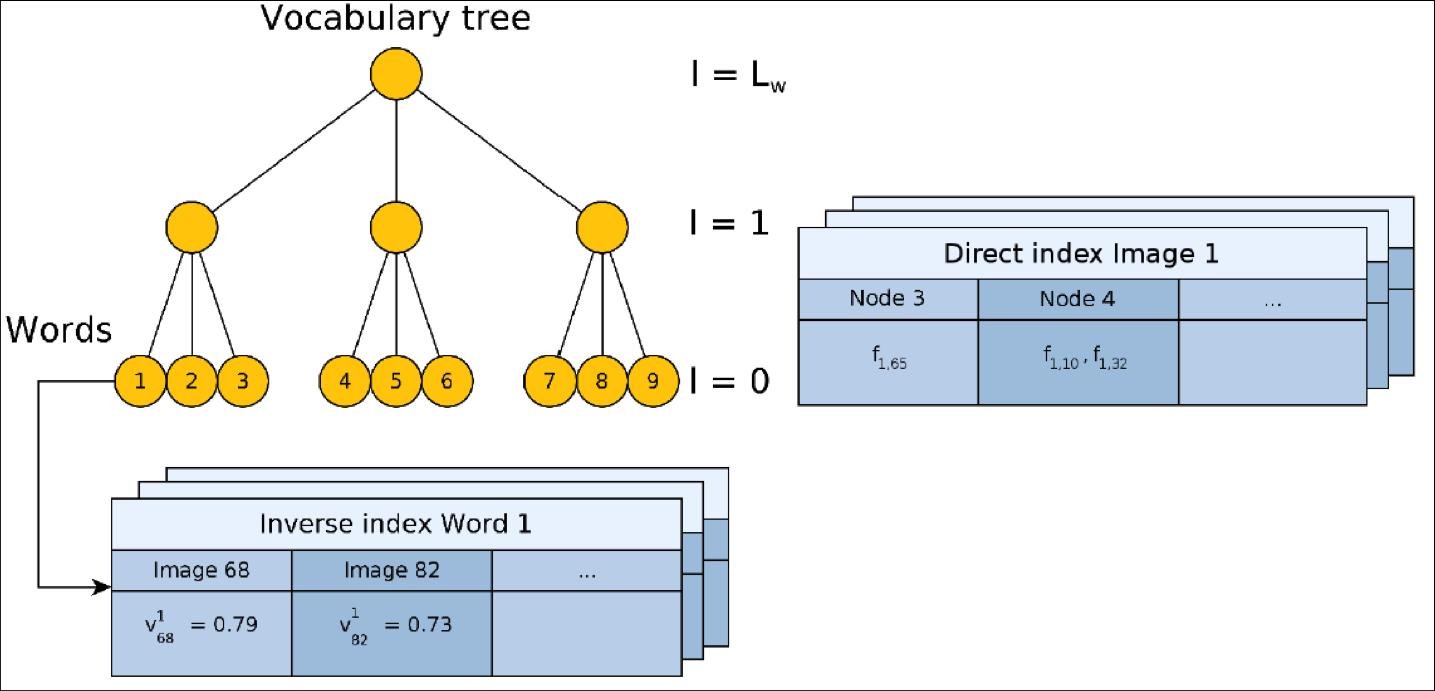
主要采用 K-means算法,将用于训练的图像数据库中的视觉特征(DBoW3中支持ORB和BRIEF两种二进制描述子)归入k个簇(cluster)中,每一个簇通过其质心(centroid)来描述,聚类的质量通常可以用同一个簇的误差平方和(Sum of Squared Error,SSE)来表示,SSE越小表示同一个簇的数据点越接近于其质心,聚类效果也越好。这里的“接近”是使用距离度量方法来实现的,不同的距离度量方法也会对聚类效果造成影响(后面会提到)。
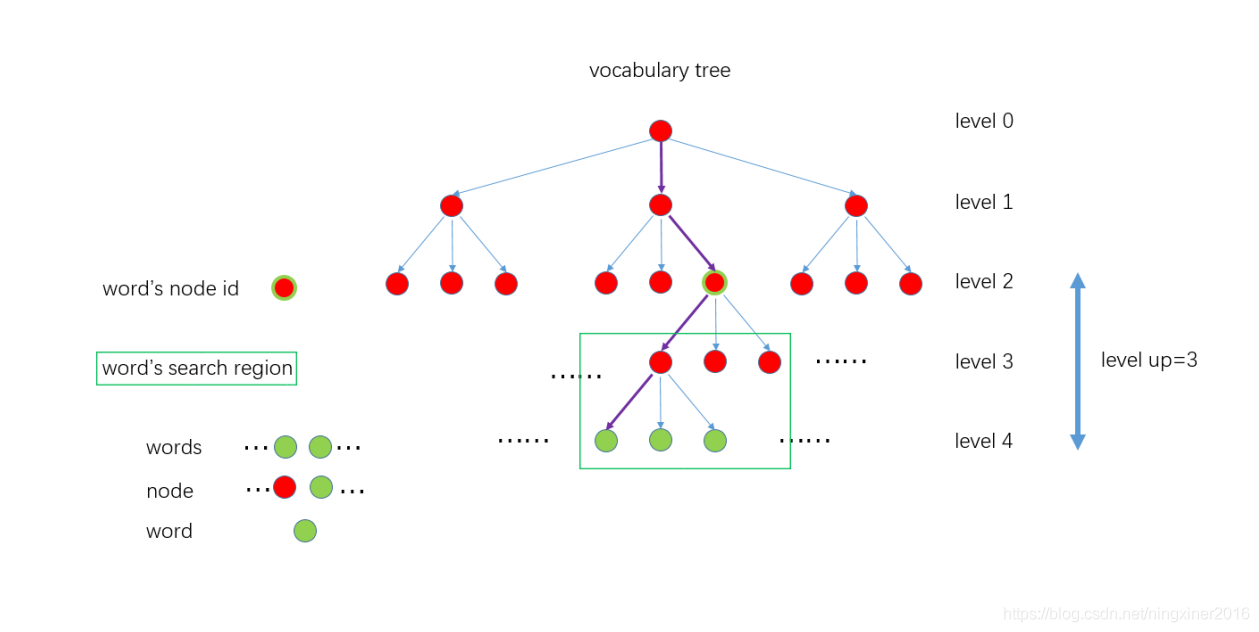
将训练图像数据库中所有N个描述子分散在一个k分支,d深度的k叉树的叶子节点上,如分支数为3,深度为 \(L_w\),这样一个树结构有叶子结点 \(3^{L_w}\) 个。可以根据场景大小、需要达到的效果修改k和d的数值。这样query image进来检索时,可以通过对数时间的复杂度(d次 = logk N)找到其对应的聚类中心,而不是使用O(n)的时间复杂度的暴力检索。据统计,在10000张train image图像数据库中找到query image的匹配图像耗时<39ms,并有较高的召回率和较低的false positive。
然后,为了提高检索时的效率、成功率以及准确率,还采用了下述 权重计算算法
K-means优点是容易实现,缺点是在大规模数据集上收敛较慢,并且可能收敛到局部最小,造成该簇没有代表性。对于描述子这种高维空间的大规模聚类,粗暴使用K-means会有问题。因此会使用其变种Hierarchical K-means 或 K-means++。
k-means++代码在如下函数:
1 | |
由于ORB和BRIEF描述子均为二进制,因此距离度量采用汉明距离(二进制异或计算)。query image的描述子通过在字典的树上检索(找到最近邻的叶子节点)视觉单词,组成一个词袋向量(BoW vector),然后进行词袋向量之间的相似度计算,得到可能匹配的ranking images。最后还需要利用几何验证等方法选出正确(只是概率最大。。。)的那张图片。
ORB SLAM中, 在利用帧间所有特征点比对初始化地图点以后, 后面的帧间比对都采用Feature vector进行, 而不再利用所有特征点的descriptor两两比对。这样做的好处当然是 加快了处理速度, 但是信息再次被压缩抽象化, 不可避免会造成性能降低。 然而根据作者在之前的文章[1]及github上的描述, 对一幅图片的BOW特征抽取可以在5ms以内完成, 而在19000张图片构成的database中, 图片搜索可以在10ms内完成, 且保证False Positive为0。 具体的实验我没有进行验证, Whatever, ORB-SLAM证明了这样处理是有效的, 至少在数据集上, 及速度较慢的应用上, 可以实现令人满意的精度。
在作者使用的Bag of Word词典中, 词典是一个事先训练好的分类树, 而BOW特征有两种:
BowVector: 即是分类树中leaf的数值与权重
1 | |
FeatureVector: 是分类树中leaf的id值与对应输入ORB特征列表的特征序号
1 | |
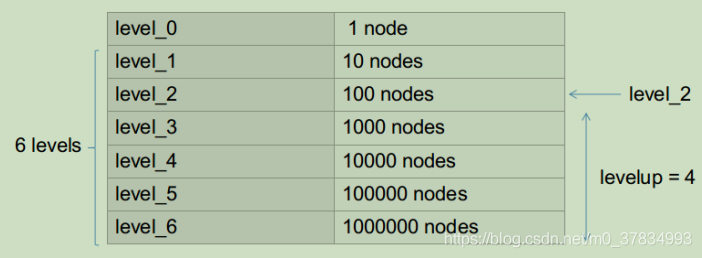
FeatureVector 是为了加速ORB slam中SearchByBow操作,如下图,对于一个6层的字典,ORB slam中levelup设置为4,则level_2的nodeid将会成为FeatureVector中的Key,而每个Key对应一张图像上的若干feature在该帧的索引值。这样在进行两帧图像的特征点匹配的时候就可以只将相同Key值下的特征描述子暴力匹配而不是对两帧图像的所有特征进行暴力匹配,达到加速算法的效果。
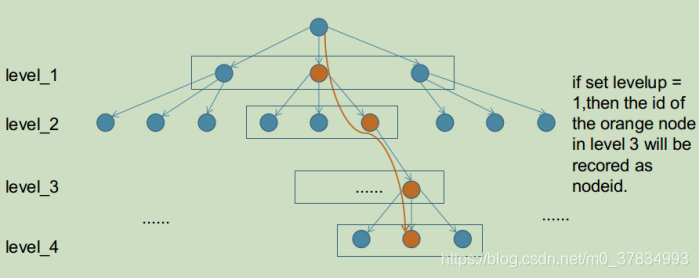
其实处理非常简单, 在已经获得图像特征点集合的基础上, 再根据词典, 对每个特征做一次分类. 再对第二幅图像提取特征, 然后也根据词典, 也对这幅图像的所有特征进行分类. 用分类后的特征类别代替原本的特征descriptor, 即用一个数字代替一个向量进行比对, 显然速度可以大大提升。
主要在以下几个函数
1 | |
核心代码如下所示:
1 | |
这种加速特征匹配的方法在ORB-SLAM2中被大量使用
作者用反向索引记录每个叶节点对应的图像编号。当识别图像时,根据反向索引选出有着公共叶节点的备选图像并计算得分,而不需要计算与所有图像的得分。
使用词袋模型,在重定位过程中找出和当前帧具有公共单词的所有关键帧,在 KeyFrameDatabase::DetectLoopCandidates() 函数中代码如下:
1 | |
to convert a set of trajectory points into a continuous-time uniform cubic cumulative b-spline
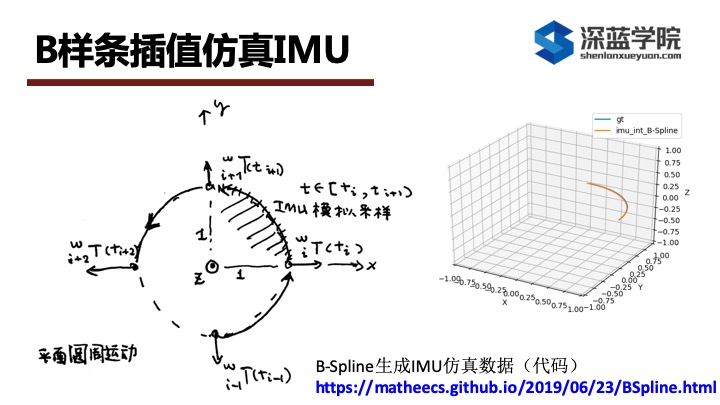
ref:
camera-imu外参标定大体上分为三步:
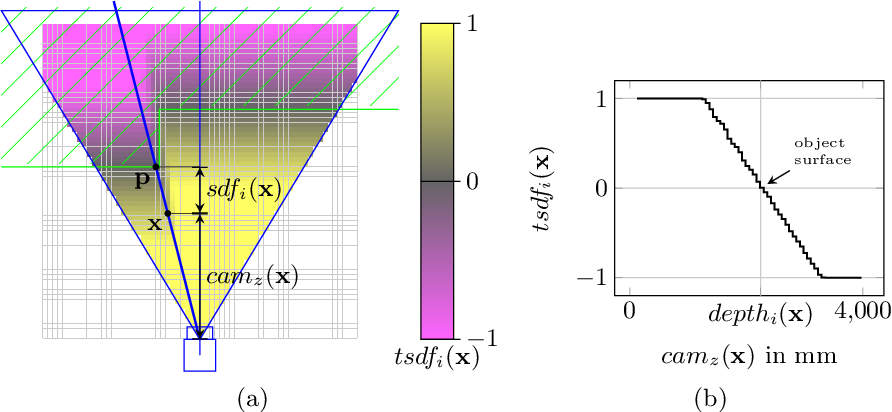
SDF (Signed Distance Function) 描述的是点到面的距离,在面上为0,在面的一边为正,另一边为负。
TSDF (Truncated SDF) 只考虑面的邻域内的SDF值,邻域的最大值是max truncation的话,则实际距离会除以max truncation这个值,达到归一化的目的,所以TSDF的值在-1到+1之间。
TSDF 模型将整个待重建的三维空间划分成网格,每个网格中存储了数值,网格模型中值的大小代表网格离重建好的表面的距离。
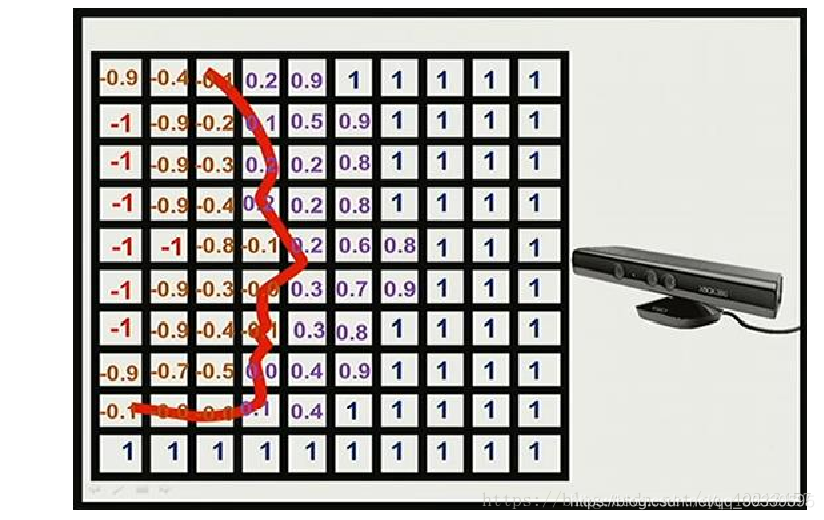
如下图表示的是重建的一个人的脸(网格模型中值为 0 的部分,红线表示重建的表面,示意图给出的二维信息,实际是三维的),重建好的表面到相机一侧都是正值,另一侧都是负值,网格点离重建好的表面距离越远绝对值越大,在网格模型中从正到负的穿越点表示重建好的场景表面。
我们将整个空间的体素全部存入GPU运算,每个线程处理一条(x,y)。即对于(x,y,z)的晶格坐标,每个GPU进程扫描处理一个(x,y)坐标下的晶格柱。
对于每个x,y坐标下的体元g,并行的从前往后扫描
将晶格坐标g转换到对应的世界坐标系点vg
对于每次TSDF操作时的拍摄变换Ti反变换到对应的相机坐标系坐标v
将wi和tsdfavg存储在对应的晶格,进行下个晶格的扫描操作 经过上面的扫描,最终立方体晶格中存储的tsdf值形成了重建物体外是负值,物体内部是正值,物体表面是0值得形式(可能没有准确的零值,但是可以根据正负值插值求出零值点,所以最后物体表面的分辨率将会超过晶格的分辨率)
要建立一个长方体包围盒,让所有的三维点都在这个长方体里面。
假设z方向垂直相机,则x,y方向上的极值就是图像的边界。图像的边界点是就是四个角 (0,0),(w,0),(0,h),(w,h),z方向上深度范围是0~max_depth,组合而成的边界点就是(0,0,0),(0,0,max_depth),(w,0,0)等的2^3=8种情况,然后把这些点用相机的内参和外参换算到世界坐标系中,长方体的极点。
在长方体内部划分网格,比如说我们现在求得的长方体的极点分别是(-1,-1,-1),(1,1,1),单位是米。我们要在这个长方体内部划分网格,就是分割出一个个等体积的小的立方体,也就是所谓的体素。我们让体素的边长是0.02,也就是2厘米。那么从-1到1,我们可以划分出100个体素,也就是说这个长方体上每个小立方体的8个顶点的坐标可以用(x,y,z)来表示,其中x,y,z都是0-100之间的,同时它们的世界坐标也可以通过(-1+0.02x,-1+0.02y,-1+0.02*z)来计算出来。
遍历每一组数据(RGB图、深度图、pose.txt),每次把这个长方体内的所有格点的世界坐标通过逆变换到相机坐标,再投影到图片上。
将图片上对应位置的深度与格点的在相机坐标系下的深度比较
\[\text{depth-diff} = \text{depth-val} - \text{cam-pts}[2,:]\]
如果 \(\|\text{depth-diff}\| < \text{trunc-marin}\) 则认为有效。
用 \(\text{dist} = \text{depth-diff} / \text{trunc-marin}\) 去加权更新tsdf网格。
tsdf网格每个顶点存放的是dist的加权和。
用marching cubes算法在tsdf网格中寻找dist加权和为0的等值面,就是物体表面。
https://github.com/andyzeng/tsdf-fusion
https://github.com/andyzeng/tsdf-fusion-python 🚩
http://www.open3d.org/docs/0.12.0/tutorial/pipelines/rgbd_integration.html#TSDF-volume-integration
\[z = f(x) + n, \quad n \sim \mathcal{N}(0, \Sigma), \quad z \sim \mathcal{N}(f(x), \Sigma)\]
\[P(z \mid x) = \mathcal{N}(z; f(x), \Sigma) = \eta \exp \left(-\frac{1}{2}(z-f(x))^{T} {\Sigma}^{-1}(z-f(x))\right)\]
true state
\[\begin{aligned}x_k &= f(x_{k-1}, w_{k-1}) \\z_k &= h(x_k, v_k)\end{aligned}\]
norminal state
\[\begin{aligned}\bar{x}_k &= f(\hat{x}_{k-1}, 0) \\\bar{z}_k &= h(\bar{x}, 0)\end{aligned}\]
true state linearization
\[\begin{aligned}x_k &\approx \bar{x}_k + A(x_{k-1} - \hat{x}_{k-1}) + W w_{k-1} \\z_k &\approx \bar{z}_k + H(x_k - \bar{x}_k) + V v_k\end{aligned}\]
prediction error & measurement residual
\[\begin{aligned}e_x &\equiv x_k - \bar{x}_k \approx A(x_{k-1} - \hat{x}_{k-1}) + W w_{k-1} \\e_z &\equiv z_k - \bar{z}_k \approx H e_x + V v_k\end{aligned}\]
jacobian
\[A = \frac{\partial f}{\partial x}, \quadW = \frac{\partial f}{\partial w}\]
\[H = \frac{\partial h}{\partial x}, \quadV = \frac{\partial h}{\partial v}\]
covariance
\[w \sim \mathcal{N}(0, Q), \quad v \sim \mathcal{N}(0, R)\]
\[e_x \sim \mathcal{N}(0, P) \rightarrow x \sim \mathcal{N}(\bar{x}, P), \quad e_z \sim \mathcal{N}(0, S)\]
\[P = \texttt{cov}(e_x) = E(e_x e_x^T), \quad S = \texttt{cov}(e_z) = E(e_z e_z^T)\]
state prediction (w/o noise)
\[\hat{x}_k^- = f(\hat{x}_{k-1}, 0)\]
(error state) covariance
\[\text{cov}(x_k - \hat{x}_k^-) = P_k^- = A_k P_{k-1} A_k^T + W_k Q_{k-1} W_k^T\]
Kalman gain
\[K_k = P_k^- H_k^T S^{-1}, \quad S = H_k P_k^- H_k^T + V_k R_k V_k^T\]
state update
\[\hat{x}_k = \hat{x}_k^- + K_k (z_k - h(\hat{x}_k^-, 0))\]
covariance update
\[\text{cov}(x_k - \hat{x}_k) = P_k = (I - K_k H_k) P_k^-\]
\[PVQ\]
continuous-time to discret-time,离散时间 状态转移矩阵和噪声协方差矩阵 比较准确,例如
\[F = \exp(A \Delta t) \approxI + A \Delta t + \frac{1}{2} (A \Delta t)^2 + \frac{1}{6} (A \Delta t)^3\]
误差状态的概率分布
\[\delta x \sim \mathcal{N}(\hat{\delta x}, P), \quad n \sim \mathcal{N}(0, Q)\]
误差协方差传播(整个系统过程)
\[\delta x_{i+1} = F \delta x_i + G n, \quad P = F P F^T + G Q G^T\]
\[\delta x \sim \mathcal{N}(\hat{\delta x}, P)\]
\[z = h(x) + v \approx h(x_0) + H \delta x + v, \quad v \sim \mathcal{N}(0, R)\]
predicted residual (innovation)
\[r = z - h(x_0) = H \delta x + v\]
then, the covariance of innovation
\[cov(r, r) = E(rr^T) = E(H \delta x \delta x^T H^T + vv^T) = HPH^T + R\]
\[x = K r\]
\[P = (I-KH)P\]
\[PVQ\]
continuous-time to discret-time
\[F = \exp(A \Delta t) \approx I + A \Delta t\]
误差状态的概率分布
\[\delta x \sim \mathcal{N}(0, P), \quad n \sim \mathcal{N}(0, Q)\]
误差状态(状态预积分)和协方差传播(图像k时刻初始,图像k~图像k+1)
\[\delta x_{i+1} = F \delta x_i + G n, \quad P = F P F^T + G Q G^T\]
\[J = \frac{\partial r}{\partial \delta x}\]
协方差矩阵(信息矩阵的逆)
\[\text{cov}(\delta x_k) = P\]
协方差矩阵(信息矩阵的逆)
\[\text{cov}(r_k) = \Sigma_{\pi}\]
\[x = x + \delta x\]
欧式空间的非线性方程
\[h(x) \approx h(x_0) + H \Delta x, \quad \left. H = \frac{\partial h(x)}{\partial x} \right|_{x = x_0}\]
当 \(h(x)\) 线性时
\[h(x) = Hx\]
\[f(x_0 \oplus \Delta x) = F(\Delta x)\]
\[f(x_0 \oplus \Delta x) \approx f(x_0) + \left. \frac{\partial f(x_0 \oplus \Delta x)}{\partial x} \right|_{x=x_0} \Delta x\]
\[F(\Delta x) \approx F(0) + \left. \frac{\partial F(\Delta x)}{\partial \Delta x} \right|_{\Delta x = 0} \Delta x =f(x_0) +\left. \frac{\partial f(x_0 \oplus \Delta x)}{\partial \Delta x} \right|_{\Delta x = 0} \Delta x\]
当x在欧式空间时,上式等价。
优化变量 是 什么状态,对应的 雅克比 即是 对什么状态 求导
| w.r.t true state | w.r.t error state | |
|---|---|---|
| measurement function | \(h(x)\) | \(h(\Delta x)\) |
| Jacobi | \(\frac{\partial h(x)}{\partial x}\) | \(\frac{\partial h(x)}{\partial \Delta x}\) |
| init state | \(x = x_0\) | \({\Delta x}=0\) |
| update | \(x \oplus \Delta x, \Delta x = Kr\) | \(\Delta x = Kr\) |
| w.r.t true-state | w.r.t error-state | |
|---|---|---|
| cost function | \(f(x)\) | \(f(\Delta x)\) |
| Jacobi | \(\frac{\partial f(x)}{\partial x}\) | \(\frac{\partial f(x)}{\partial \Delta x}\) |
| init state | \(x = x_0\) | \({\Delta x}=0\) |
| iteration update | \(x \oplus \delta x\) | \(\Delta x \oplus \delta \Delta x\) |
一般表示形式
优化形式(避免过参数化)
特征的参数化表示,即以何种方式表示特征,在优化中决定了特征以何种参数进行的迭代更新,或者 在EKF中决定了以何种参数构建高斯模型。不论在优化还是EKF中,我们关心的都是特征在图像上的投影与特征参数之间的关系(Jacobian)。
特征参数化之后参数的个数大于实际表示的 自由度 的表现形式就被称为 过参数化
\[P: \left[ X \; Y \; Z \right]^T\]
ref:
\[L: \left[ P_0 \; P_1 \right]\]
ref:
\[Ax + By + Cz + D = 0\]
ref:
用一个平面的 单位法向量 和 平面距离原点的 距离 来表示
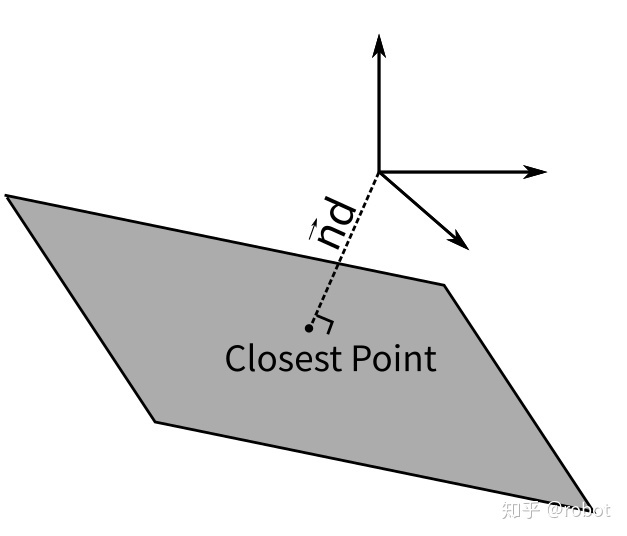
\[\pi: \left(\mathbf{n}^{\top}, d\right)^{\top} \in \mathbb{R}^4\]
过参数化 问题:平面的Hesse形式的过参数化就是因为单位法向量部分有3个参数,但是实际只有两个自由度导致的。
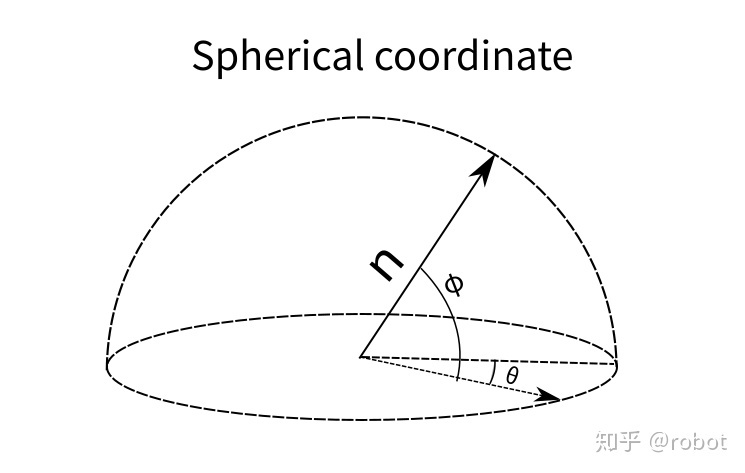
单位法向量可以被看成是一个单位圆球上的一点,那么就可以用两个角度 \(\theta\) 和 \(\phi\) 来参数化这个点,从而表示出这个单位法向量。
\[\pi: \left[ \theta \; \phi \; d \right] \in \mathbb{R}^3\]
\[\tau=(\theta, \phi, d)^{\top}=q(\pi)=\left(\theta=\arctan \frac{n_{y}}{n_{x}}, \; \phi=\arcsin n_{z}, \; d\right)^{\top}\]
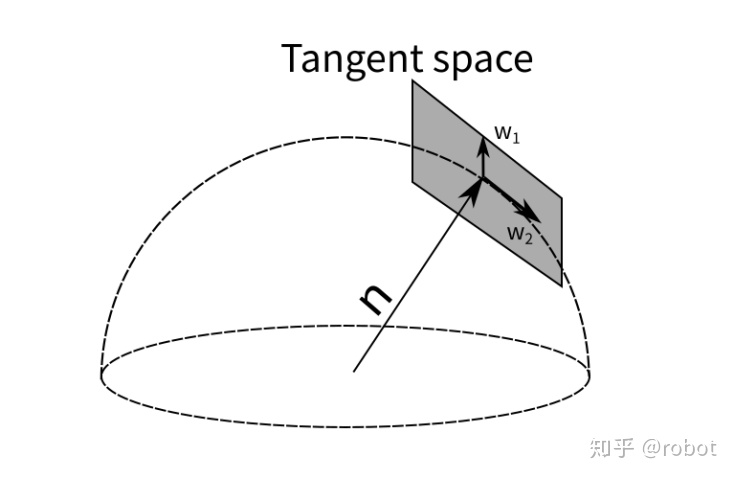
GTSAM里面表示面的方式用切平面的方式来更新单位法向量,同样也可以被用来优化单位法向量。